Introduction to Flow blockchain
About me
Hi! I am Jan (pronounced Yan). I am an Engineering Manager working on the core Flow protocol team. You may know Flow as it was created by the team that pioneered NFTs — who are famously known for breaking Ethereum with Crypto Kitties. Flow is the blockchain making decentralized applications easy to build and use by anyone.
This blog is for anyone who is interested in understanding blockchain technology. Welcome to Web3.
I have been in the tech industry for 15+ years and worked for Cisco and Amazon/AWS among other companies. When I joined Dapper Labs in the fall of 2021, I was fascinated by developments in Web3 but knew little about the tech. In this series of posts I hope to explain what I learned in a way that assumes little prior knowledge. In order to do this I will in some cases simplify things, otherwise this would turn into a white paper. I will call those simplifications out as much as possible.
Flow introduction
When Dapper Labs built Crypto Kitties we learned a lot. Most importantly, we realized that the technology at the time was not ready for this kind of application. Being the visionaries we are, we set to build a better tech for what we plan to do. We set to build what is now Flow blockchain.
One of the most significant hurdles in blockchain architecture is how to process the most amount of transactions in the least amount of time, a metric referred to as throughput. Most blockchains try to improve this by increasing the efficiency of their single node types that are used to run the network. Flow introduces a more novel and fundamental improvement for increasing the throughput by splitting the work traditionally assigned to cryptocurrency miners into different roles, where selection and ordering of transactions (consensus) are performed independently from their execution.
Node types & data flow
There are multiple entities called nodes, which contribute to the flow protocol operation and are part of the protocol network. This is a brief introduction to the 5 node types.
👀 Access Node (AN)
Access Nodes provide external clients with access to recent blocks and submit transactions from clients to the collection node cluster. They determine which collection cluster to send a transaction to (collection clusters are mapped to a range of transaction hashes).
🍇 Collection Node (LN)
Collection nodes are organized into collection clusters. Collection nodes in a cluster work together to bundle transactions into a collection. A collection node cluster decides (via a mini-consensus algorithm) which collection will be sent to the network in a form of Collection Guarantee (more on Collection Guarantees later). The Collection Guarantee can be used to get the full content of the collection and its transactions.
🤝 Consensus Node (SN)
Consensus nodes form and propose blocks based on collection information sent from collection nodes.
⛓️ Execution Node (EN)
Execution nodes execute the transactions and as a result of this update the data that is manipulated via the transactions (for example account balance when the transaction transfers tokens). Execution nodes send Execution Receipts to the network. An Execution Receipt contains an execution result, which is a hash of the data at the point in time when the execution was completed.
🔍 Verification Node (VN)
Verification nodes evaluate the correctness of the work done by execution nodes. Verification node submits a Result Approval to the network. Result Approvals are matched with Execution Results by Consensus nodes to check validity of execution.
This is how the data flow in the network looks like at a very high level:

💡 The Consensus Committee uses HotStuff consensus protocol to achieve consensus for a proposed block. A detailed protocol description can be found in the HotStuff protocol white paper.
Why so many different node types, you may ask ? Let me explain. Our goal is to build a blockchain that delivers high performance and is easy to develop for, unlike layer-2/sharded solutions which achieve the performance at the cost of increased complexity for application developers. We achieve this goal by splitting the traditional role of a blockchain node into multiple roles, which gives us more flexibility in scaling the network (separation of concerns). We have split the selection and ordering of the transactions, transaction execution, block formation (consensus) and transaction execution verification to separate roles. This enabled us to build a network with uncompromised security and decentralization guarantees while at the same time concentrating the computationally expensive operations to a small group of high-performance nodes.
Let’s take a closer look at the data and the role different components play in achieving the high efficiency of the network.
The transaction throughput of the overall system depends on the efficiency of the consensus algorithm, which is run by consensus nodes, one of the four main node types. We often refer to consensus nodes as the consensus committee. After the collection nodes have formed incoming transactions from users into collections, they send them to the consensus committee. The nodes in the committee must quickly come to a consensus on the order of collections in blocks. As you could imagine, the speed of this is very sensitive to the block size, because the block needs to be distributed to all the nodes in the consensus committee. Flow protocol achieves high efficiency by not including the content of the transactions in the block. Instead, the block only contains commitments by the collection nodes that the collection will be accessible by the network, called a Collection Guarantee, which is basically a collection identifier. Collection guarantees are added to a block by the consensus leader. Since they are mostly just simple identifiers instead of large transactions, the nodes can process an order them much faster.
Once the block is proposed by the consensus leader, it can be processed by the Execution nodes. Execution nodes monitor the activity on the p2p network and look for newly proposed blocks to be executed that are provided by the consensus committee. An Execution node will use the collection guarantees in the block to request collection content from the collection nodes to execute the transactions in the collection. Block execution needs to be done sequentially to ensure correctness of the result (changing the order of transactions would produce different results and parallel execution of transactions brings another set of challenges that are beyond the scope of this post). For this reason, the speed of execution is essential to the transaction throughput. Execution nodes are required to be data-centre sized machines with a lot of compute power and memory.
When the block is executed, each Execution node publishes an execution result, which needs to be verified by Verification nodes to ensure the execution was done correctly. Verification means executing the transaction and comparing the result with the execution result published by the execution node. As opposed to block execution, block verification can be parallelized, because each transaction execution result can be verified independently. This means that verification is easy to scale horizontally (multiple verification nodes verifying different transactions in parallel). The parallelization of the verification process is done by splitting a block into chunks. A verification node determines the chunk assignment from an execution result contained in a block and requests the chunk data pack from the execution node. Verification nodes send their result approvals to the network, consensus nodes use the result approvals to verify the block execution and finally seal the block (we will go through this process in much more detail in future posts).
💡 In the Flow protocol implementation as of March 2022, chunks are identical to Collections (1 to 1 mapping). Collection is to be executed, Chunk is a collection that has been executed.
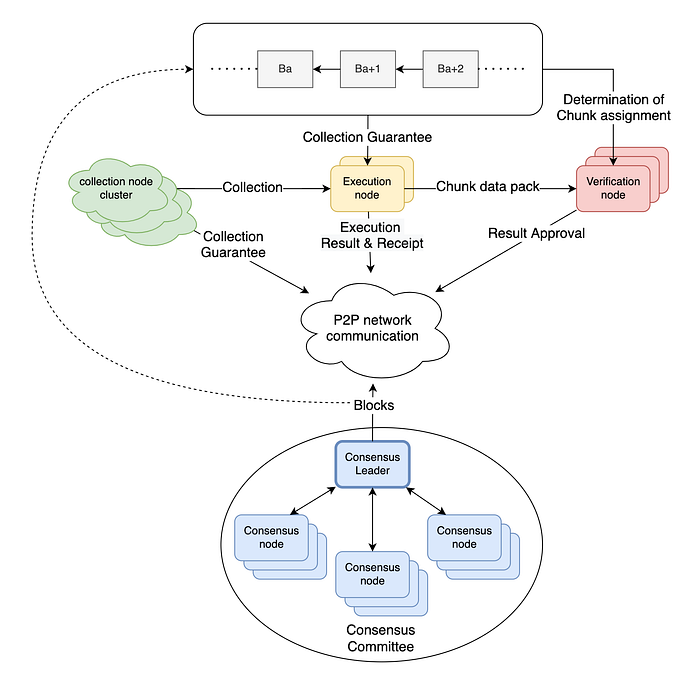
Hopefully by now the high-level data flow is clear. In the following posts we will look in more detail at the different stages of the block and transaction lifecycle and also at data storage. Before we do that, we will go through the protocol timing, because that is something that was a bit of revelation for me when I was exploring the protocol and I think it is critical in understanding the other concepts.
Useful links
Flow technical papers: https://www.onflow.org/technical-paper
